
Written by coh at home
[자료구조] HashSet과 HashTable/HashMap 본문
결론부터 말하면
자바의 HashSet은 Contains()의 시간복잡도가 O(1)이다.
hash함수를 적용한 값을 버킷에 담고 있기 때문에 특정 문자열을 찾는 속도가 상수시간만큼 걸리는 것이다.
HashTable은 가장 기초적인 자료구조로 Key와 Value의 pair이다. 키값을 해쉬화해서 인덱스로 만든 후 버킷의 인덱스에 자료를 저장하게 된다. HashMap도 똑같이 동작한다.
똑같이 동작한다면 왜 두 개의 컬렉션 라이브러리가 있는 것일까?
결론부터 말하면 동기화 여부와 null허용 여부이다.
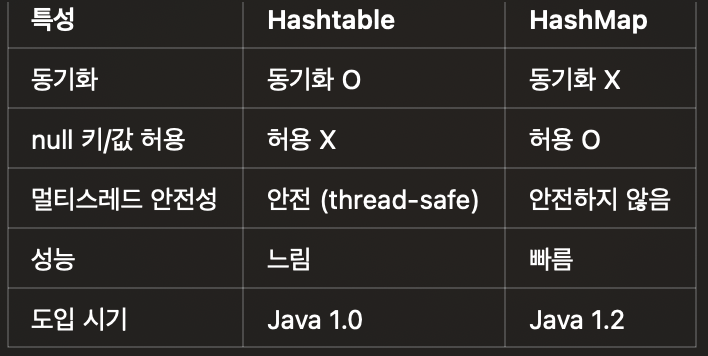
HashTable은 자바 1.0부터 나왔고 HashMap은 자바1.2부터 나왔다.
HashTable은 동기화가 설정되어 있고 HashMap은 동기화가 설정되지 않았다. 따라서 속도는 HashMap이 빠르나 멀티스레드에서 사용하기 적합하지 않다. 맵 자료구조에서 멀티스레드 환경을 지원하려면 이때는 ConcurrentMap을 사용하면 멀티스레드 환경에서도 사용 가능한 것으로 알고 있다.
HashTable은 null키값을 허용하지 않으나 HashMap은 허용한다.
정리하면 다음과 같다.
다음은 HashSet과 관련된 백준 1764 듣보잡 문제이다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.HashSet;
import java.util.Map;
import java.util.PriorityQueue;
public class NoSeeHear {
public static void main(String[] args) throws Exception{
HashSet<String> noSee = new HashSet<>();
PriorityQueue<String> noHear = new PriorityQueue<>();
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] datas = br.readLine().split(" ");
int n = Integer.parseInt(datas[0]);
int m = Integer.parseInt(datas[1]);
for (int i = 0; i < n; i++) {
noSee.add(br.readLine());
}
for (int i = 0; i < m; i++) {
String name = br.readLine();
if (noSee.contains(name))
noHear.add(name);
}
System.out.println(noHear.size());
while (!noHear.isEmpty()) {
System.out.println(noHear.poll());
}
}
}
'CS > 자료구조 알고리즘' 카테고리의 다른 글
| 백준으로 살펴보는 이분탐색과 부분합. (0) | 2024.10.20 |
|---|