
Written by coh at home
[CUDA]Intro and structure 본문
1. Intro

CPU는 보통 코어 수가 12개 이하이다. 이에 반해 GPU는 수천 개의 코어가 있고 그래서 many core라고 부른다.
다음은 성능표이다.
CPU에 비해 엄청 많은 코어와 FLOPS라는 용어가 보인다. FLOPS는 floating points를 얼마나 빨리 처리할 수 있는지에 대한 지표를 알려준다. floating points operation per second.
CPU도 FLOPS에 대한 성능표가 존재한다. 하지만 이는 GPU에 비하면 상당히 느린 속도이다.
음.. 근데 왜 core수가 GPU가 CPU에 비해 엄청 많은 걸까?
비유를 하자면 CPU는 고등학생 6명, GPU는 사칙연산만 할줄 아는 초등학생 수천명을 core라고 할 수 있다. 즉, 후자는 단순반복 연산을 잘하는 수천 개의 core이다.
AI의 발전과 함께 GPU는 많은 양의 data를 병렬적으로 처리하기 위해 Memory Bandwidth가 급격하게 증가하는 모습을 볼 수 있다.
GPU의 core수가 많을 수 있는 이유는 다른 대상에 대한 dependency가 없다는 데에 있다. 그냥 자신에게 주어진 task만 처리하면 된다! 어떤 사물을 rendering할 때 단위 삼각형으로 잘라서 빛, 반사, 등등의 요소를 고려하는데 이때 각 단위삼각형은 independent하게 core에서 연산을 할 수 있어서 core수가 점점 더 많아지게 되었다!!
여담으로 메타버스에서 고화질의 연산을 하는 GPU를 통해 메타버스를 구현하는 것이 중요할지 생각해볼 필요가 있다.
e.g. 마인크래프트
XR or AR로 발전할 수도 있다.
다음은 NVIDIA's revenue이다.
Data Center의 수익 증대를 좀 눈여겨 볼 필요가 있다. 사실상 AI processor라고 불러야하지 않나..
GPU는 고대역폭, 즉, 많은 data를 사용하는 분야에서는 진짜 성능이 압도적이다.
2. 병렬처리
single core CPU에서
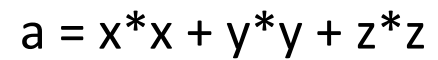
와 같은 연산을 하기 위한 명령어는

이때 각 명령어가 한 cycle이라고 하면 5번의 cycle이 필요하다.
cycle을 줄이기 위해 명령어 수준에서 병렬화을 하면(ILP)
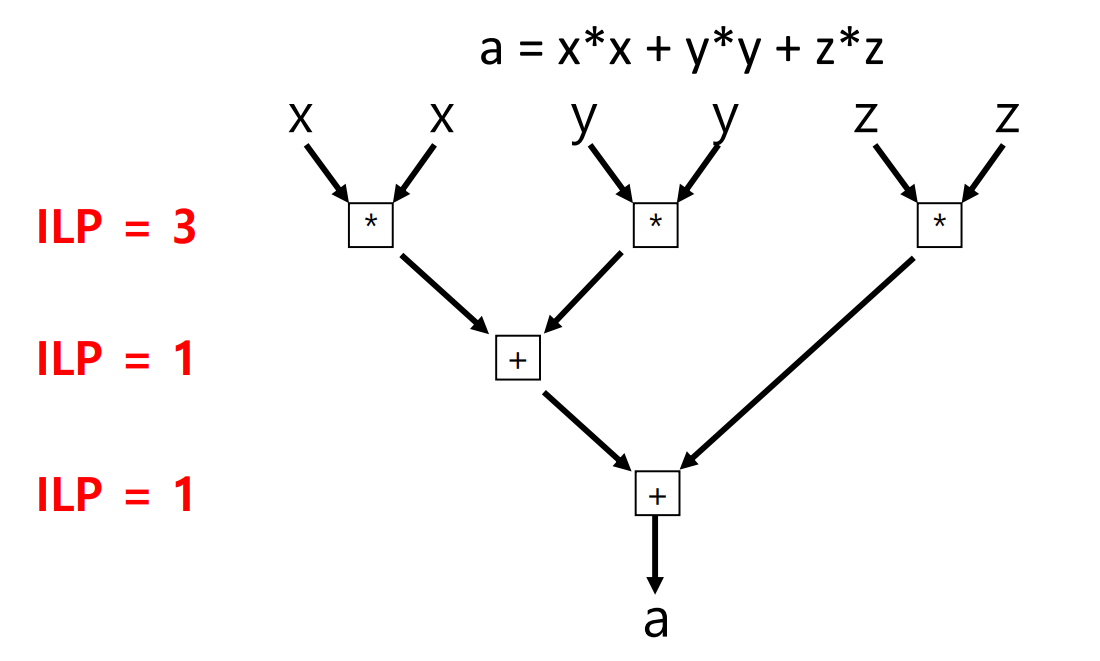
ILP를 n배 증가시키는 것은 n개의 multiplication을 더 증가시키는 것이다.
dependency가 없는 명령어를 찾는 것은 쉽지 않아서 결국 한계에 봉착한다.
마찬가지로 freq를 통한 clock 향상도 결국 한계에 봉착한다.
그래서 등장한 것이 concurrency revolution이름으로 등장한 multi core이다.

여담으로 애플의 M1은 ILP에서 dependency가 없는 것을 먼저 처리하는 것을 잘했고 그래서 성능이 좋다. 당시 동 컴퓨터 대비 300개 이상..

다음은 무어의 법칙인데 multicore의 등장으로 계속 트랜지스터의 집적도는 올라가나 Single thread performance는 점점 수렴하는 모습이 보여진다.
그래서 Parallel하게 처리하는 것이 중요하고 GPU는 CPU보다는 복잡하지않은 단순 연산들을 엄청 많이 할 수 있는 core들을 많이 보유하고 있다. SSD가 빠른 이유도 내부적으로 병렬적으로 처리를 다 하기 때문. 이는 스마트워치, TV 등등 임베디드 장비들도 마찬가지이다.

GPU의 구조이다. thread는 CUDA core이다.
CPU는 latency에 초점이 맞춰져있다. (e.g. 링크 클릭)
GPU는 Throughput에 초점이 맞춰져있다. (4k화면 데이터 입력받아서 한번에 렌더링)
memory bandwidth가 중요하다.

그래서 CPU는 단일연산성능 때문에 ALU가 GPU보다 크고 범용워크로드 지원을 위해 control 유닛도 큰 것을 볼 수 있다.
반면에 GPU는 ALU가 작고 많은 수의 ALU가 Control unit에 묶인 것을 확인 할 수 있다.